
在这篇笔记中,我们(指我和 Gemini)开启了一场有趣的探索:传统机器学习能否像读者一样,感知到不同作者的文字风格?我们不仅将使用 Wolfram 语言内置函数 Classify 构建一个分类模型,更希望通过一系列可视化,直观地“看见”文字背后的风格印记。
灵感来源于 Wolfram 的官方示例:Find Which Author Wrote a Text。
完整文件结构
为了让项目清晰有序,我们采用以下文件结构。所有代码和数据都围绕这个结构展开。
1 | 中文作家识别项目/ |
区分不同作者
不妨从一个经典的二分类开始,作为文体分析的“热身运动”:区分两位风格鲜明的作家——骆以军和阎连科。
1. 数据集构建
我们选取了两位作家的各五部作品,并使用 Calibre 软件将它们统一转换为 .txt 纯文本格式,存放在上述 Dataset 文件夹中。
接下来,我们使用 Wolfram Language 来加载和处理这些数据。
1 | (* --- 1. 定义数据集目录 --- *) |
2. 构建训练与测试集
机器学习模型需要大量的“学习材料”。我们的策略是将每位作者的所有文本合并,然后切分成固定长度(这里设定为 1000 个字符)的文本片段。每个片段都是一个独立的样本,用于训练和测试。
1 | (* 定义每个文本片段(样本)的目标字符数 *) |
数据准备好后,我们将其按 80/20 的比例分割成训练集(用于训练模型)和测试集(用于评估模型性能)。
1 | (* 将每个作者的数据随机打乱 *) |
3. 训练分类器并验证结果
一切准备就绪,我们开始训练分类器。Wolfram Language 内置的 Classify 函数会自动为我们处理好复杂的模型选择。
1 | authorClassifier = Classify[trainingSet]; |
模型训练完成后,我们用之前留出的测试集来检验它的表现。
1 | cm = ClassifierMeasurements[authorClassifier, testSet] |
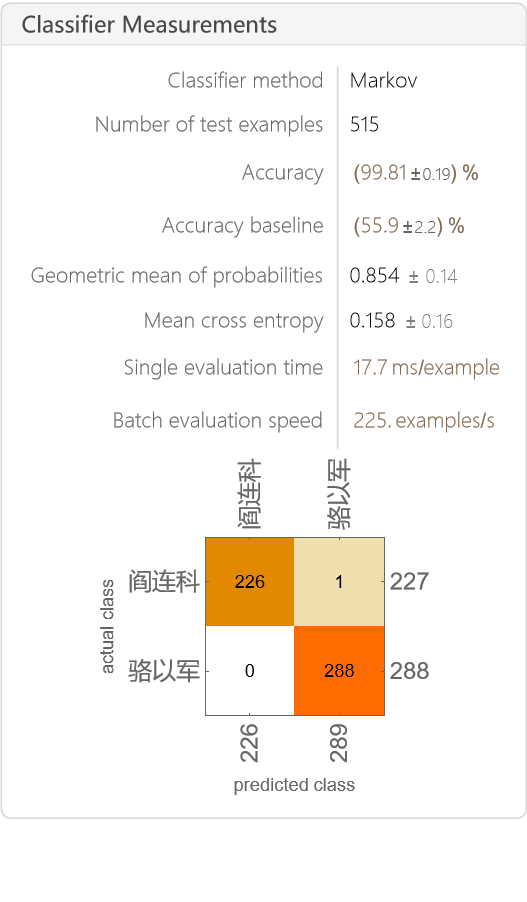
模型给出的成绩单非常亮眼,准确率达到了 99.81%!混淆矩阵(Confusion Matrix)也清晰地显示,在 515 次测试中,模型几乎“百发百中”。这直观地告诉我们,骆以军和阎连科的文体风格差异巨大,模型可以轻松地将他们区分开。
另外,模型没能区分开的这一段(cm["WorstClassifiedExamples" -> 1])其实比较特殊,并非小说正文,而是阎连科的一篇创作谈。
4. 在全新文本上测试
为了进一步感受模型的“实战”能力,我们找来了两段全新的文本,分别来自骆以军的《明朝》和阎连科的《中国故事》,让模型进行预测。模型自信地给出了正确答案 {"骆以军", "阎连科"},展现了其强大的泛化能力。
1 | testText = { |
但对于阎连科的《速求共眠》,分类器遇到了障碍,可见此书在阎连科创作谱系中占据了独特位置。不过,也可能只是因为所选文段中使用括号来补充说明,这有点像是骆以军的风格了。
1 | suqiugongmian={"知道吗,今日中国电影票房正呈井喷之势。有人预计今年电影票房是二百亿,而明年全国票房最低二百六十亿,后年为三百亿。请你算一下,如果今年拍摄,明年上映,凭你我之努力,顾长卫之号召力,我们在中国电影票房中的二百六十亿中取百分之一就是二亿六千万,百分之二就是五亿二千万,百分之三就是七个亿\[Ellipsis]\[Ellipsis]如此以保守为计,你觉得我们做一部电影没有三个亿的票房可能吗?而我们的这部电影投资小,场景集中,故事好看,人物丰满,在中国上映之前先到国外各大电影节上参展和参评,倘若(是肯定)撞了一个国际奖,那会是一种什么结果呢?仅仅是每人分上一千万、两千万的意义吗?","在那些取材于人民币的局部异变的巨幅现代摄影作品下,我先是有些夸张、惊讶地站着看一会儿,及至顾从楼上下来后,待他谦逊、微笑地带导着我从一楼到三楼参观他的数十幅这样的作品时,那样夸张的惊讶从我脸上消失了,留下的唯一一个念头是,他能从导演的道上暂时撤回身,做一个独一无二的现代摄影艺术家(我舍不得把"伟大"二字作为礼物送给他,因为他也从未把"伟大"作为礼物送给我),难道我就不能从写作那样清寂、孤寒中抽身出来,做一个伟大(狂妄和疯癫!)的导演和演员,摇身一变,使自己从作家变成艺术家?"}; |
区分同一作者的不同小说
既然区分不同作者如此轻松,一个更有趣的问题浮现了:模型能否感知到同一位作者在不同作品中细微的风格变化?
我们选择数据集中骆以军的五部小说,来开启这场更具挑战性的探索。
1. 数据准备
这次,我们的分析单元变成了“书名”。数据处理的逻辑与之前类似,但这次我们是按单个文件(即单本书)来创建标签和数据集。
1 | bookFiles = FileNames["*.txt", FileNameJoin[{NotebookDirectory[], "Dataset/骆以军"}]]; |
2. 训练与评估
我们重复之前的步骤,对这五本书的数据进行分割、训练和评估。
1 | (* 将每本书的数据随机打乱并分割数据集 *) |
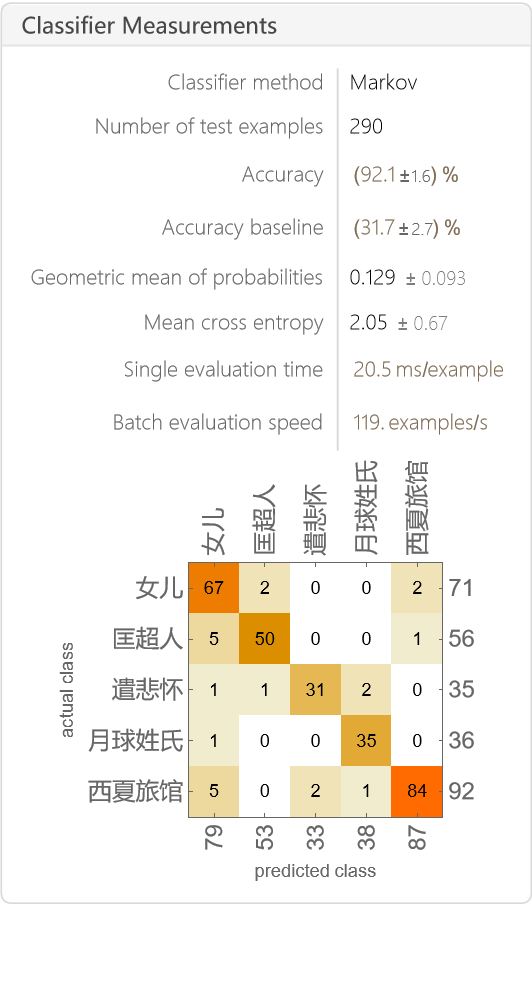
这次,模型的准确率约为 92.1%。混淆矩阵显示,模型大部分时候都能做出正确判断,但也出现了不少混淆。这揭示了一个有趣的现象:
- 骆以军的不同作品之间确实存在可以被量化的风格差异。
- 但这些差异非常细微,导致模型时常会感到困惑,尤其当不同作品探讨相似主题时,它们的微观文风可能会趋同。
同样,我们用上一部分骆以军《明朝》“机器人上吊”的片段,来测试第二个分类器:
1 | singleTestText = testText[[1]]; |
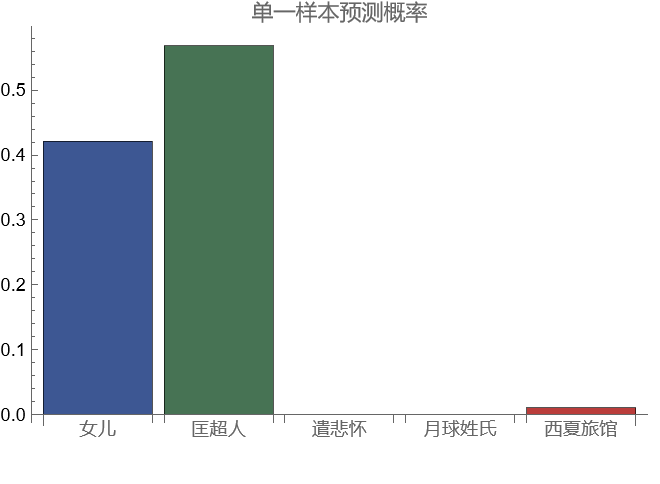
分类器认为这段来自《女儿》或者《匡超人》。我猜测这是因为这两本小说同样提及了“AI 机器人”这个话题。
可视化文体空间
为了更直观地理解模型是如何“看见”这些细微差异和困惑的,我们需要一种方法来绘制一幅“文体地图”。特征空间降维可视化正是为此而生的强大工具,读取每个文本片段的“文风特征”,然后将文风相似的片段放在地图上相近的位置。
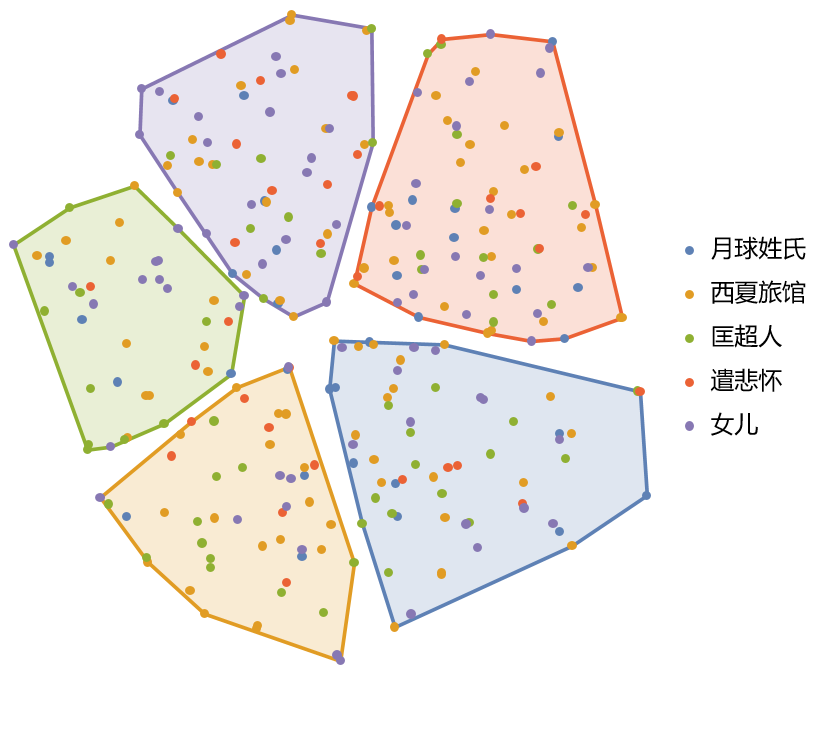
第一眼看去,这幅地图似乎有些“混乱”,所有颜色的点都均匀地混合在一起。这本身就是一个非常有价值的视觉呈现,它直观地告诉我们:骆以军的个人文体风格非常统一,以至于在 1000 个字符的微观尺度上,他的不同作品几乎“你中有我,我中有你”。
我们能否从这片“混沌”中找到隐藏的结构?我们引入 K-Means 聚类算法,让它在完全不知道书名的情况下,自动地在地图上寻找 5 个“点最密集的社区”。
这张最终的可视化地图,是本次探索之旅的核心发现。
- 每一个小圆点,代表一个长度为 1000 个字符的文本片段。点的颜色代表它来自哪本书。
- 每一个背景色块,代表一个由算法自动发现的、“文体风格上高度相似”的文本片段社区。我们可以称之为一种“写作模式”或“风格集群”。
每一个背景色块(风格集群)中,都包含了五颜六色的点(来自所有不同的书)。
这幅图景生动地展示了:骆以军在创作任何一部小说时,都会反复运用(或陷入)他几种标志性的“写作模式”。例如,某个色块可能汇集了他所有作品中那些关于“家庭记忆和身体创伤”的片段,而另一个色块则可能聚集了那些“引用典故、进行哲学思辨”的片段。
如有雷同,纯属巧合。
可视化代码如下:
1 | (* --- 1. 数据准备与降维 --- *) |
25/06/22
