
既然有多模态功能,如何用 Gemini 识别并转换一整本扫描版 PDF?
低效能人士的七个习惯
我读书读得很凶的那段时间,买过一个 APP 的会员,不是月度的,一直用到现在。APP 叫“白描”,拍照识别文字内容(又称 OCR,“光学字符识别”),方便用来做书摘。
你能感觉技术日臻成熟,软件也更好用了。
但还是有瑕疵。
——标点识别出来会有些问题,比如省略号经常识别成独立的几个点,还往往不是六个。
——断句很奇怪,不是按照图中的分段来的,要么勤得像现代诗人,要么懒得像萨拉马戈。
这些都是小问题,后来有些需求就无法满足了。
——有些电子书很难找到,只有扫描版的 PDF 文件(就算不错了),如果要放进 6 寸阅读器,字就会很小,这该怎么办呢?
正解是换一个大一些的电子书,但我的解法比较经济,是找了裁切 PDF 的工具,但在阅读器上看还是很别扭,如果要做笔记也没法直接划线,还是要用“白描”。
怪不得一直用到现在。
后来白描有了网页版,可以导入 PDF,之后就变成面板中的一张张图片,可以批量识别。
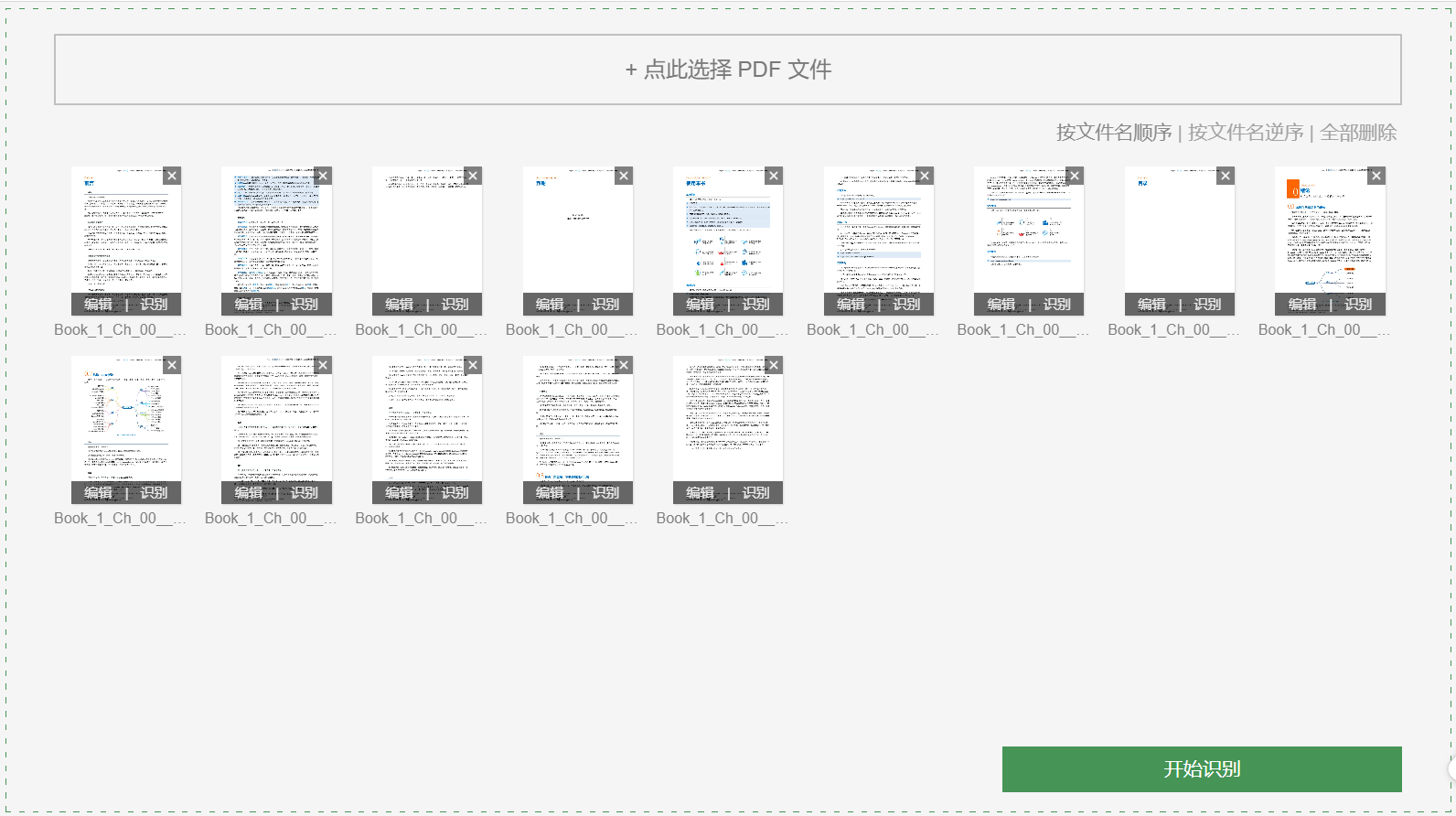
看上去很美,用起来很是麻烦。
一是一次最多转换 50 页,你需要用 Acrobat 之类的 PDF 编辑软件预处理一番。二是不能像书摘一样单独选择识别范围,所以识别出来的内容往往包含页眉页脚,分页处也自然被截成了两段,你需要比照着 PDF 文件,用肉眼做一些后处理……那为什么不直接读 PDF 呢?
等待一个什么
说来也怪,我没有找其他更好用的 OCR 软件。不是没有,只是没有去找。一直等到多模态大模型成熟,等到人们习以为常,我才想起那些 PDF 来。
前些日子看到一段 “元提示词”,沟通几轮、实操几轮之后,添加了繁转简、统一标点和识别公式等功能。最终得到了这样的 OCR 任务提示词:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 请处理我上传的PDF文件,本次任务只专注于 **[在此处填写章节名称或编号]** 的内容,并将其精确地转换为Markdown格式。
在转换过程中,必须严格遵守以下规则:
1. **范围限定:** 仅提取并转换指定章节的内容。忽略文件中的其他所有部分。
2. **内容忠实:** 除了执行必要的繁简与标点转换外,绝不概括、增加或删除原文的任何句子或段落。
3. **繁体转简体:** 智能判断原文语种。如果原文是繁体中文,请在转换格式的同时,将所有文字内容平滑地转换为简体中文。
4. **统一中文标点:** 如果文本主要是中文,请将所有英文标点符号转换为对应的中文全角标点符号(此规则不适用于代码块和公式)。
5. **清理页面元素:** 删除所有页码、页眉和页脚。
6. **合并断裂段落:** 将因分页符而断开的句子和段落连接起来。
7. **精确格式化:** 将原文的所有格式(如标题、列表、粗体、斜体、引用、脚注、数学公式等)准确转换为标准的GitHub Flavored Markdown。**特别注意**:任何数学对象必须转换为LaTeX格式(行内用`$...$`,块级用`$$...$$`),并确保代码块和表格被正确格式化。
8. **保留诗歌格式:** 如果原文中包含诗歌,请在转换时保持其特有的断句和格式不变。
请开始处理指定的章节。
|
是的,我因为输出长度的关系放弃了“一镜到底”,转而选择按照书中的章节输出。一般情况下,大模型可以完整输出一章的文字。事实上有些书从头到尾就是一段,不过我还没碰上,就没考虑这些极端案例。
还要注意,我是在 Google AI Studio 用的 Gemini 2.5 Pro 模型,把模型温度设为 $0.2$(机械性任务的温度应该设置得低一些),然后关闭联网,不让摸鱼。
以下是几个案例:
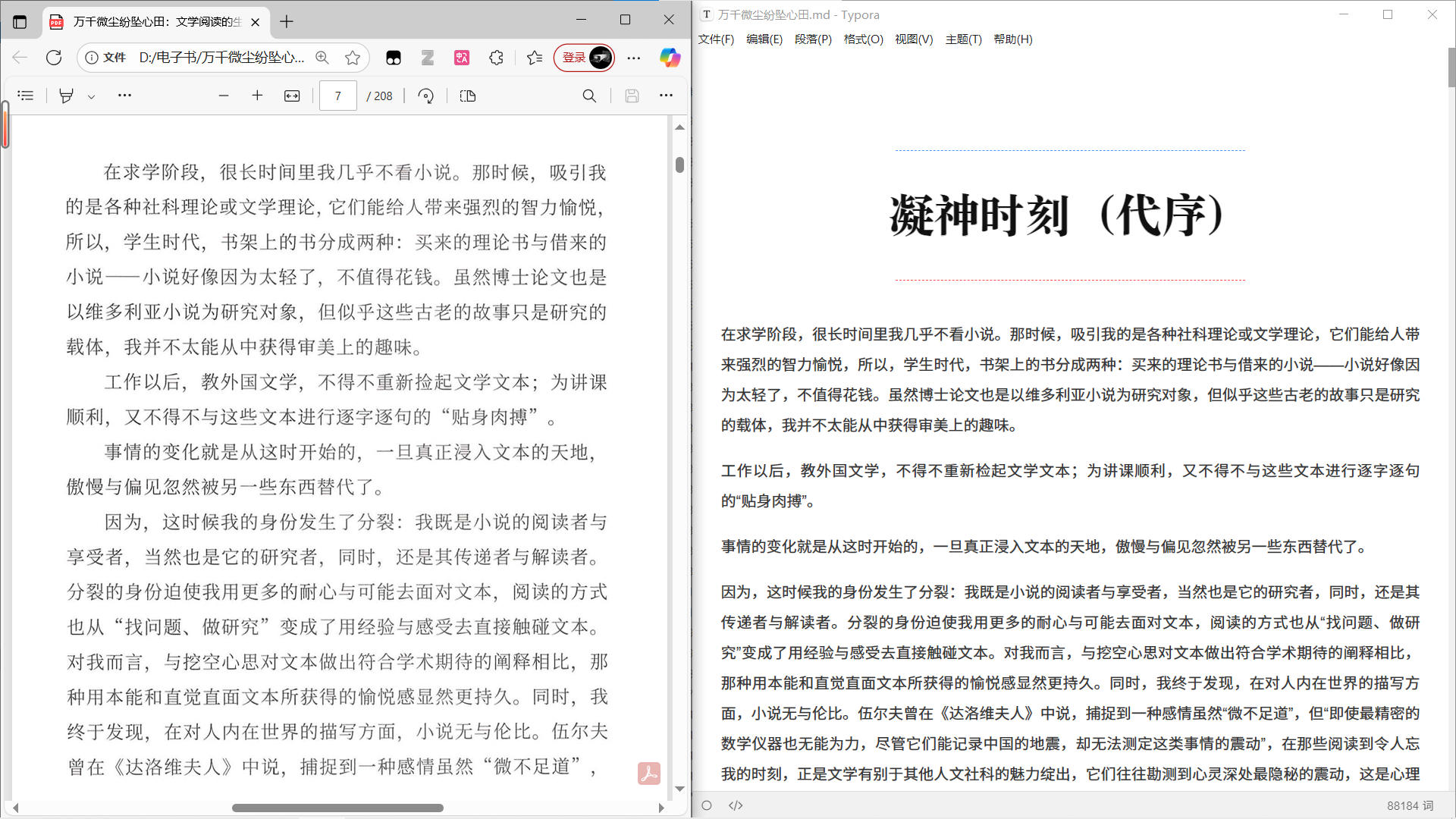
1️⃣ 扫描比较清楚的简体书:经过浏览我没有看出需要编辑的地方。
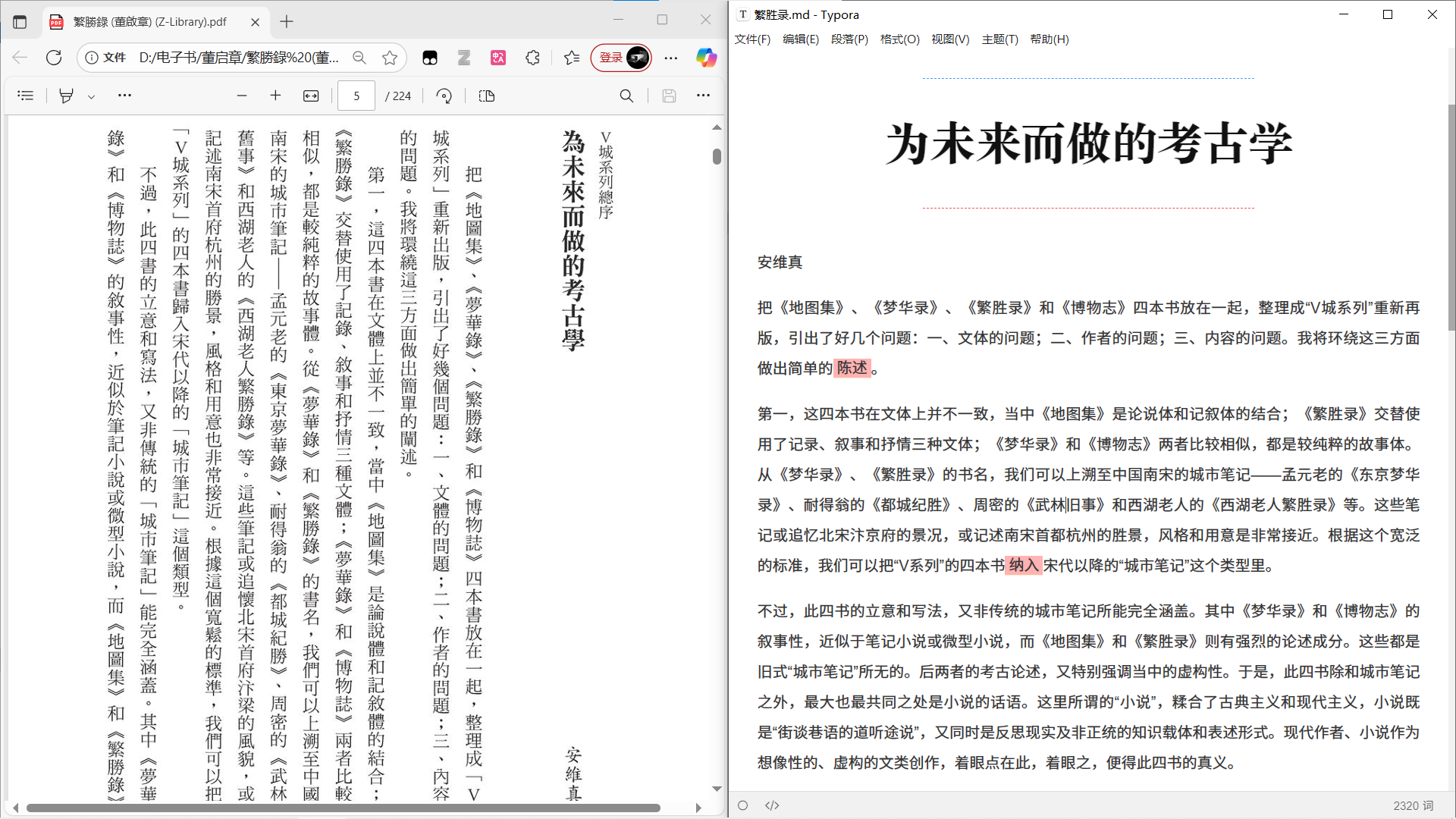
2️⃣ 扫描比较清楚的竖排繁体书:截图内容里,大模型做了两次“同义替换”。其实这是一个缺点,你很难看出大模型改动了哪里,像一些译者所做的事。
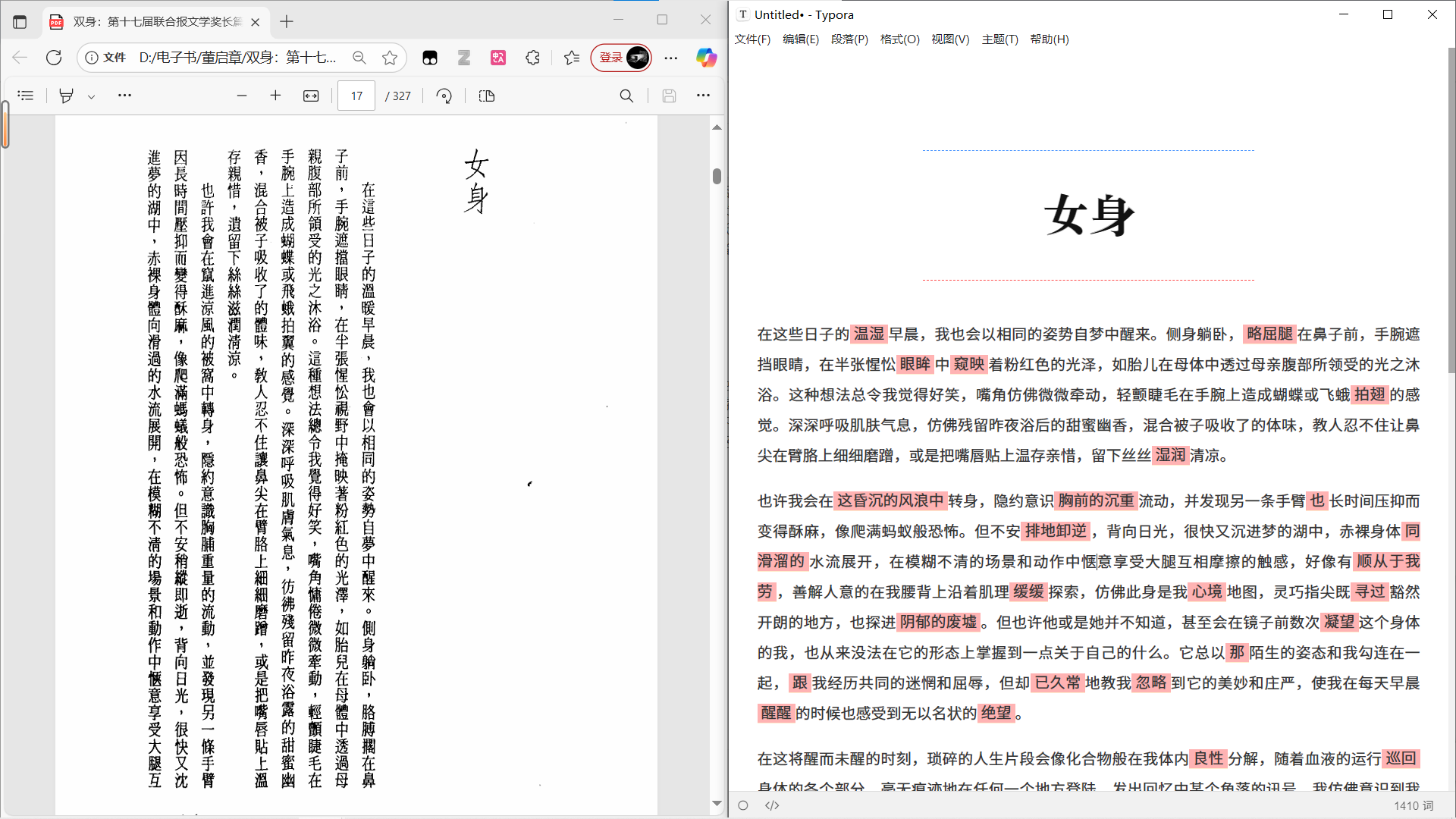
3️⃣ 扫描不太清楚的繁体书:找到了大模型的能力边界——如果是“老派扫描”,模型看不清就是看不清,提示词再好也白搭。另外,前面提到的缺点变得更明显了,就像高明的厨师能做得你尝不出老鼠屎来。
4️⃣ 公式很多的书:你能看到公式的细节有些变化,我同样标红了。另外,公式多的书往往也有很多插图,今天讲到的方法对此完全无效。
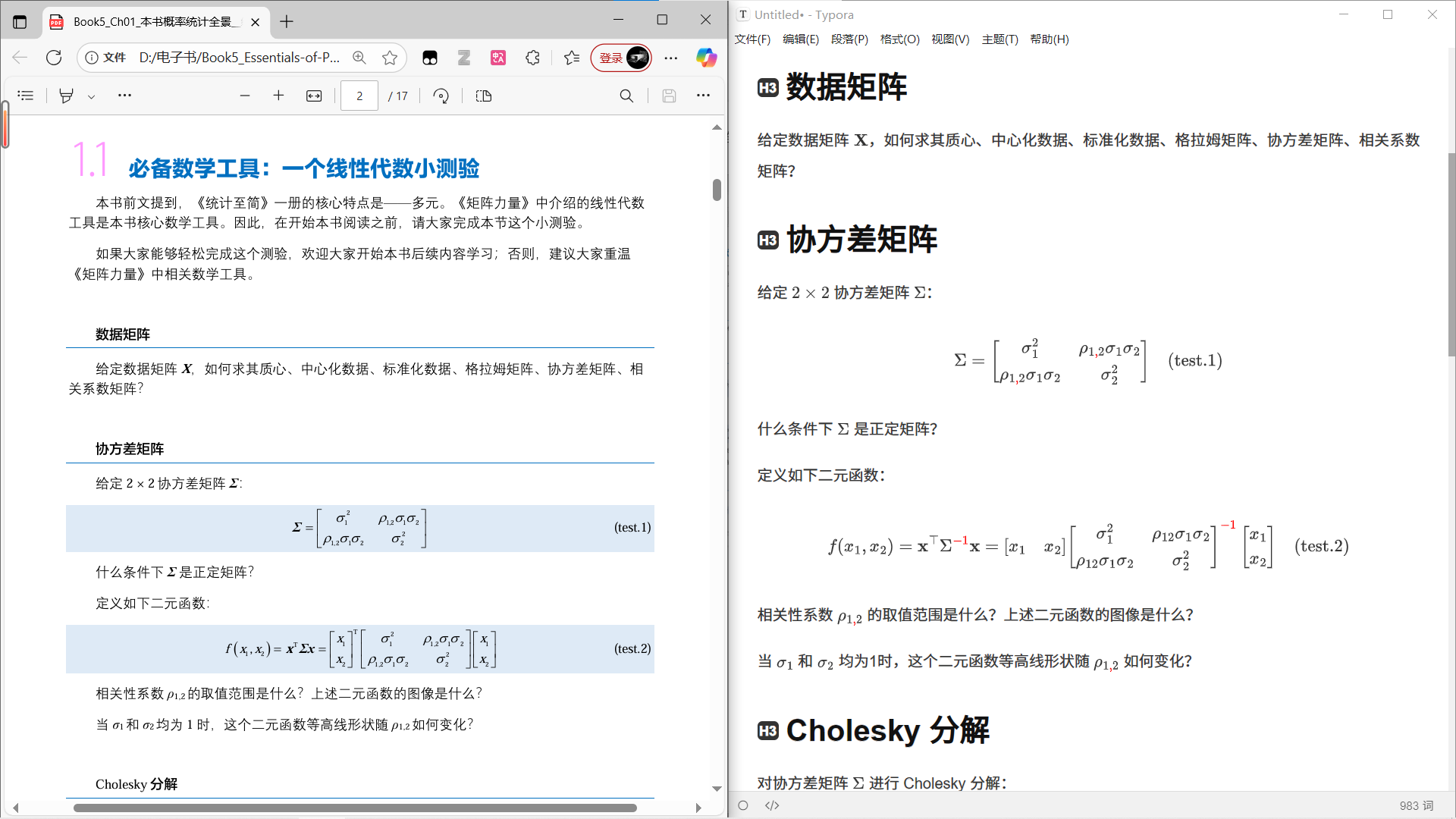
5️⃣ “闪灵”问题。

实验中几次出现了“结巴”,根据我的臆测,一种是由于上文内容太多,此时新开窗口可以解决。
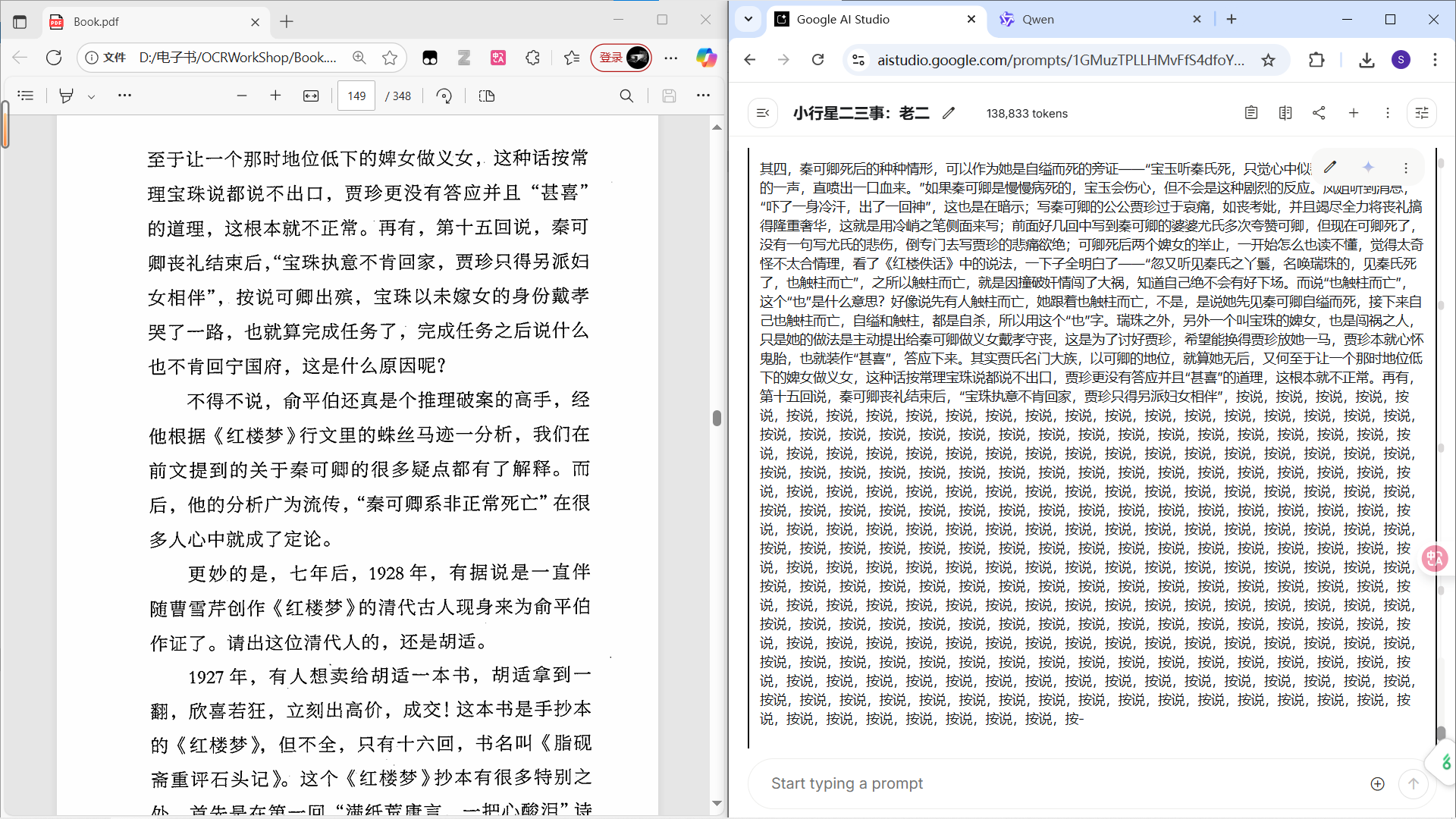
另一种则是文本本身的问题,比较接近“贯口”,比如董启章的《繁胜录》(作者在后记里说“用顿号写成的小说”),有的章节开新窗口也不管用。
这说明,不练贯口就上台容易结巴。

立等不可取
为了解决顿号密集的那一章内容,我突发奇想用 Gemini CLI 尝试,结果一次就完成了转换。具体原理不清楚,但应该说明窗口式 AI 和 Agent 智能体 AI 的处理逻辑有所不同。
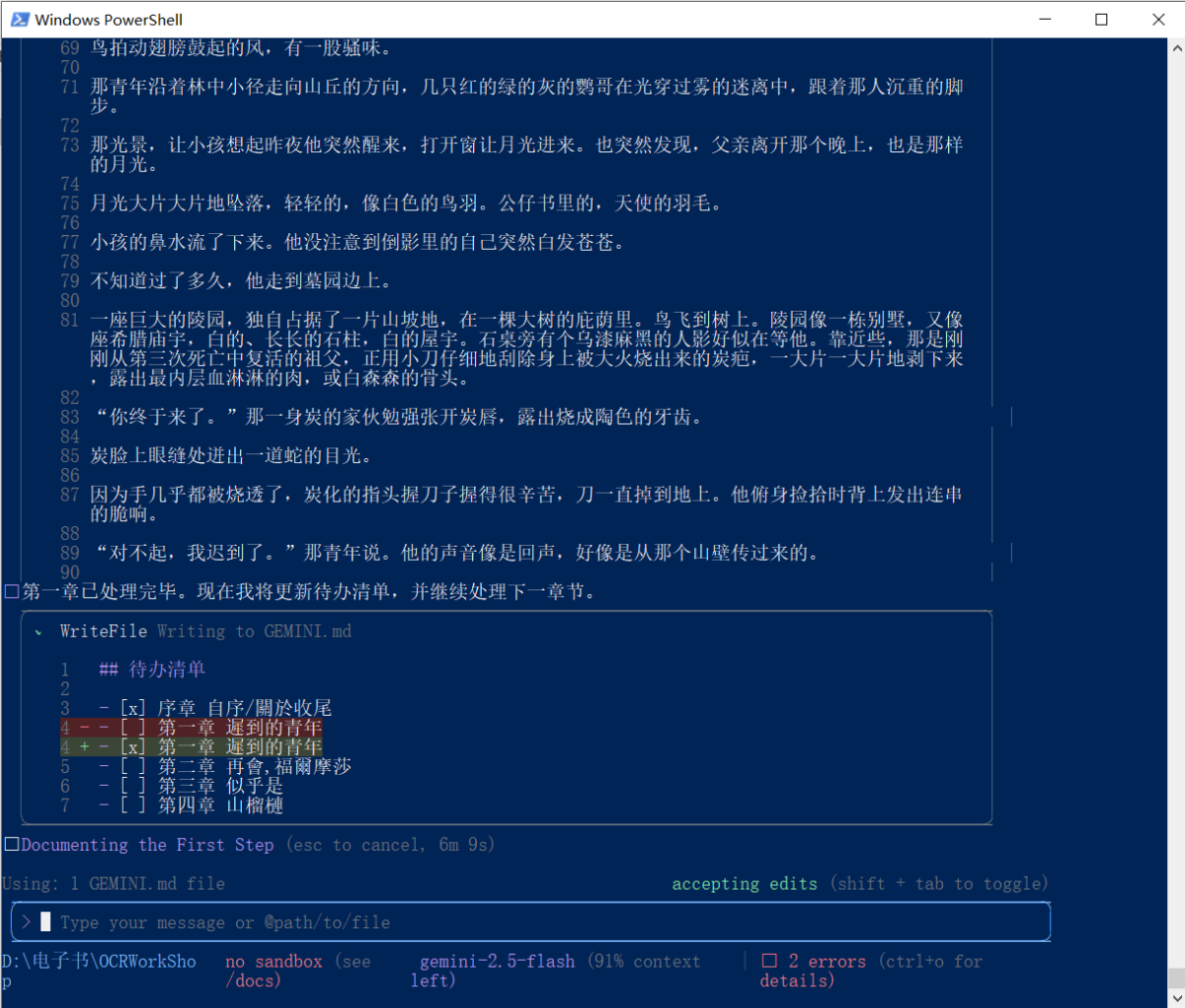
其实,用上 Agent 之后很多操作是可以简化的。我不需要自己在对话窗口中复制粘贴,直接让 Agent 写入文件就可以。我也不用在章节转换之间,说一句承上启下的“请继续下一章”,让 Agent 先自己列一个“待办清单”不就行了吗?
于是,我新建了一个文件夹 OCRWorkShop,里面包含待转换的 PDF 文件 BOOK.pdf 和提示词文件 GEMINI.md:
1
2
3
| OCRWorkShop/
├── BOOK.pdf
└── GEMINI.md
|
提示词是这样写的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| ## 待办清单
- [ ] 请在此更新待办清单
## 全书分章操作
请处理我上传的PDF文件:
1. 将PDF的目录列写为markdown格式的 `待办清单`;
2. 按照清单顺序,执行 `章节具体操作`;
3. 执行完成后,在 `待办清单` 中进行标记,并顺序执行下一章节,不需要用户提醒;
4. 根据清单顺序,使用shell的 `copy` 命令将各章markdown文件合并成一个,例如 `copy 文件1.md + 文件2.md + 文件3.md 合并文件.md`。
格式示例:
- [x] 第一章 酒樓之城
- [x] 第二章 小食之城
- [ ] 第三章 傀儡之城
## 章节具体处理
请处理我上传的PDF文件,每次任务只专注于指定章节的内容,并将其精确地转换为markdown格式。注意:每章内容存入独立的markdown文件中。
在转换过程中,必须严格遵守以下规则:
1. **范围限定:** 仅提取并转换指定章节的内容。忽略文件中的其他所有部分。
2. **内容忠实:** 除了执行必要的繁简与标点转换外,绝不概括、增加或删除原文的任何句子或段落。
3. **繁体转简体:** 智能判断原文语种。如果原文是繁体中文,请在转换格式的同时,将所有文字内容平滑地转换为简体中文。
4. **统一中文标点:** 如果文本主要是中文,请将所有英文标点符号转换为对应的中文全角标点符号(此规则不适用于代码块和公式)。
5. **清理页面元素:** 删除所有页码、页眉和页脚。
6. **合并断裂段落:** 将因分页符而断开的句子和段落连接起来。
7. **精确格式化:** 将原文的所有格式(如标题、列表、粗体、斜体、引用、数学公式等)准确转换为标准的GitHub Flavored markdown。**特别注意**:任何数学对象必须转换为LaTeX格式(行内用$...$,块级用$...$),并确保代码块和表格被正确格式化。
8. **保留诗歌格式:** 如果原文中包含诗歌,请在转换时保持其特有的断句和格式不变。
请开始处理指定的章节。
|
待办清单,实现任务自动化。各章节独立文件,防止 Agent 把“写入”变成“替换”(真的会发生)。还能怎么提升效率,多 Agents 并行运算?
不管了,做午饭的工夫,全自动完成了一本书的转换。
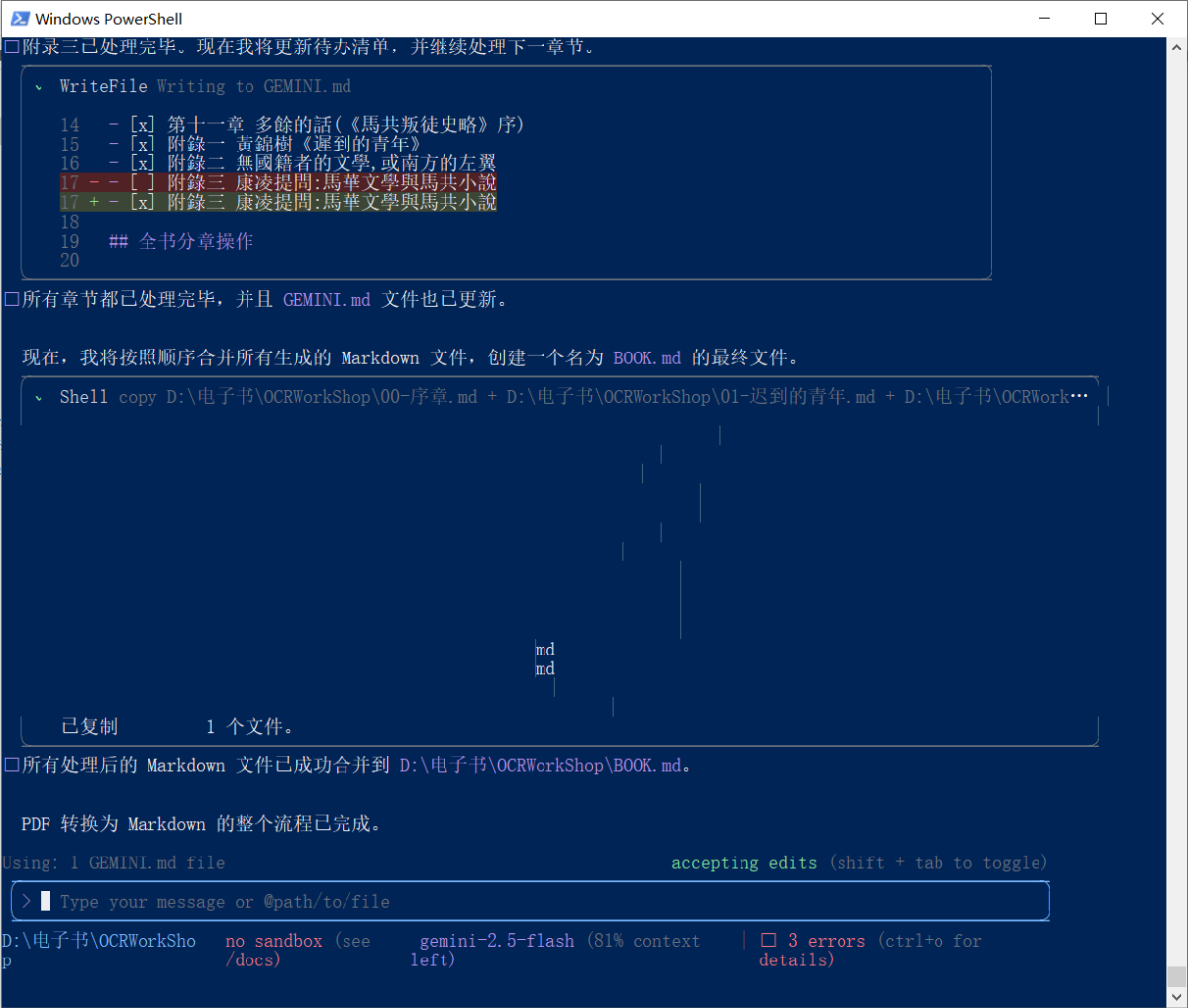
很满意……我也是后来发现有漏转换章节,才没那么满意的。
Agent 确实吸引人,既全自动又不需要自己编程。但问题也很突出,有一种智力是不可再生资源,但在任务中却始终均等挥霍的感觉,眼瞅着越来越傻,简直是衰老的隐喻。
另一个问题是慢。怎么能和我做饭一样慢呢?
前面说的窗口式 AI,你虽然腾不出手来,但完成任务能快上不少,哪怕同样使用思考模型。
也许是我等得还不够,Agent 还得再等等。
小结
模型配置:
- 网站:Google AI Studio
- 型号:Gemini 2.5 Pro
- 温度:0.2
- 联网:关闭
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 请处理我上传的PDF文件,本次任务只专注于 **[在此处填写章节名称或编号]** 的内容,并将其精确地转换为Markdown格式。
在转换过程中,必须严格遵守以下规则:
1. **范围限定:** 仅提取并转换指定章节的内容。忽略文件中的其他所有部分。
2. **内容忠实:** 除了执行必要的繁简与标点转换外,绝不概括、增加或删除原文的任何句子或段落。
3. **繁体转简体:** 智能判断原文语种。如果原文是繁体中文,请在转换格式的同时,将所有文字内容平滑地转换为简体中文。
4. **统一中文标点:** 如果文本主要是中文,请将所有英文标点符号转换为对应的中文全角标点符号(此规则不适用于代码块和公式)。
5. **清理页面元素:** 删除所有页码、页眉和页脚。
6. **合并断裂段落:** 将因分页符而断开的句子和段落连接起来。
7. **精确格式化:** 将原文的所有格式(如标题、列表、粗体、斜体、引用、脚注、数学公式等)准确转换为标准的GitHub Flavored Markdown。**特别注意**:任何数学对象必须转换为LaTeX格式(行内用`$...$`,块级用`$$...$$`),并确保代码块和表格被正确格式化。
8. **保留诗歌格式:** 如果原文中包含诗歌,请在转换时保持其特有的断句和格式不变。
请开始处理指定的章节。
|
或者直接使用 GeminiCLI,GEMINI.md 文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| ## 待办清单
- [ ] 请在此更新待办清单
## 全书分章操作
请处理我上传的PDF文件:
1. 将PDF的目录列写为markdown格式的 `待办清单`;
2. 按照清单顺序,执行 `章节具体操作`;
3. 执行完成后,在 `待办清单` 中进行标记,并顺序执行下一章节,不需要用户提醒;
4. 根据清单顺序,使用shell的 `copy` 命令将各章markdown文件合并成一个,例如 `copy 文件1.md + 文件2.md + 文件3.md 合并文件.md`。
格式示例:
- [x] 第一章 酒樓之城
- [x] 第二章 小食之城
- [ ] 第三章 傀儡之城
## 章节具体处理
请处理我上传的PDF文件,每次任务只专注于指定章节的内容,并将其精确地转换为markdown格式。注意:每章内容存入独立的markdown文件中。
在转换过程中,必须严格遵守以下规则:
1. **范围限定:** 仅提取并转换指定章节的内容。忽略文件中的其他所有部分。
2. **内容忠实:** 除了执行必要的繁简与标点转换外,绝不概括、增加或删除原文的任何句子或段落。
3. **繁体转简体:** 智能判断原文语种。如果原文是繁体中文,请在转换格式的同时,将所有文字内容平滑地转换为简体中文。
4. **统一中文标点:** 如果文本主要是中文,请将所有英文标点符号转换为对应的中文全角标点符号(此规则不适用于代码块和公式)。
5. **清理页面元素:** 删除所有页码、页眉和页脚。
6. **合并断裂段落:** 将因分页符而断开的句子和段落连接起来。
7. **精确格式化:** 将原文的所有格式(如标题、列表、粗体、斜体、引用、数学公式等)准确转换为标准的GitHub Flavored markdown。**特别注意**:任何数学对象必须转换为LaTeX格式(行内用$...$,块级用$...$),并确保代码块和表格被正确格式化。
8. **保留诗歌格式:** 如果原文中包含诗歌,请在转换时保持其特有的断句和格式不变。
请开始处理指定的章节。
|
25/09/07
